Read Article Manor Lords Early Access Review?– Strategy Game of The Year Candidate… In a Few Years Category: Reviews Reviews Manor Lords Early Access Review?– Strategy Game of The Year Candidate… In a Few Years Aleksa Stojkovi? Aleksa Stojkovi? Apr 25, 2024 3 stars
Read Article Paper Mario: The Thousand-Year Door Is the Deft Return of a Classic (Hands-On Preview) Category: Features Features Paper Mario: The Thousand-Year Door Is the Deft Return of a Classic (Hands-On Preview) Luke Hinton Luke Hinton Apr 25, 2024
Read Article Sand Land Review – Akira Toriyama’s Timeless Legacy Category: Reviews Reviews Sand Land Review – Akira Toriyama’s Timeless Legacy Syed Hamza Bakht Syed Hamza Bakht Apr 24, 2024 4 stars
Read Article Stellar Blade Review – Stylish Action Above All Category: Reviews Reviews Stellar Blade Review – Stylish Action Above All Jake Su Jake Su Apr 24, 2024 3.5 stars
Read Article Top 10 Best Games Like Shogun Category: Features Features Top 10 Best Games Like Shogun Luke Hinton Luke Hinton Apr 23, 2024
Read Article That Time I Got Reincarnated as a Slime Isekai Chronicles Announced for Summer 2024 Release Category: News News That Time I Got Reincarnated as a Slime Isekai Chronicles Announced for Summer 2024 Release Luke Hinton Luke Hinton Apr 25, 2024
Read Article Warzone Player Puts Aim Assist Argument to Bed After Proving Console Players Don’t Need It Category: News News Call of Duty Call of Duty Warzone Player Puts Aim Assist Argument to Bed After Proving Console Players Don’t Need It Nick Rivera Nick Rivera Apr 25, 2024
Read Article Dead By Daylight Players Predicted Chaos Shuffle Modifier Category: News News Dead By Daylight Players Predicted Chaos Shuffle Modifier Rowan Jones Rowan Jones Apr 24, 2024
Read Article Manor Lords Complete Trading Guide Category: Guides Guides Manor Lords Complete Trading Guide I wish my peasants knew to always tip their manor lord... Aleksa Stojkovi? Aleksa Stojkovi? Apr 26, 2024
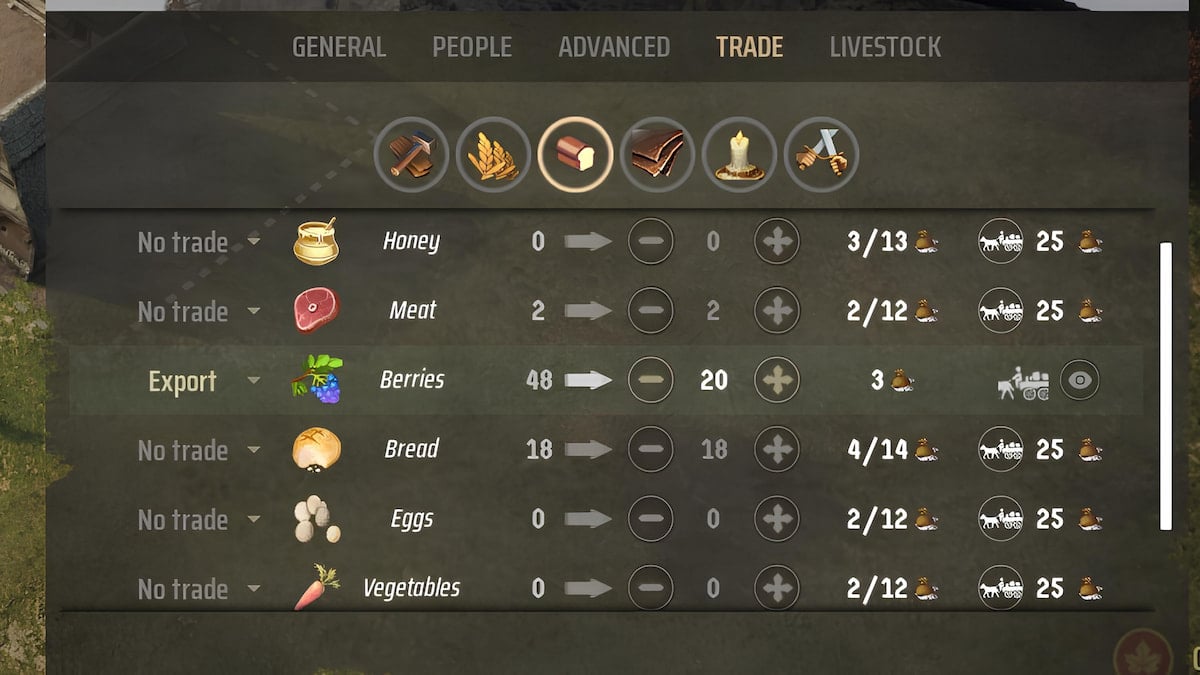
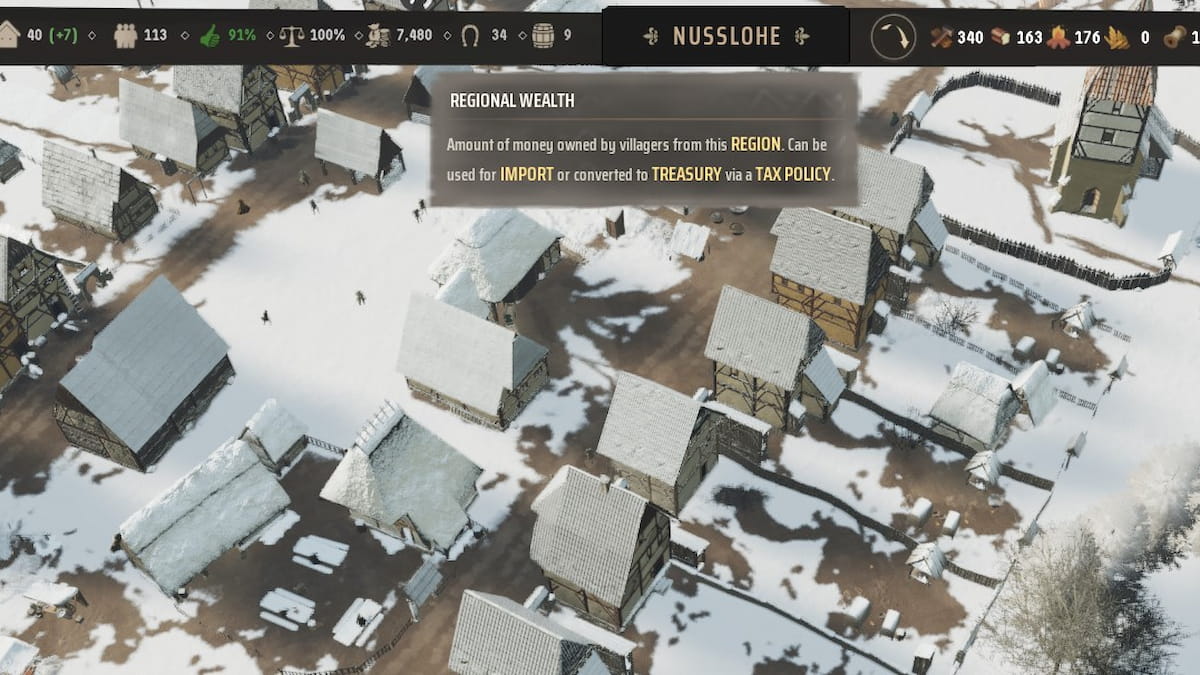
Read Article Best Export Resources in Manor Lords Category: Guides Guides Best Export Resources in Manor Lords Aleksa Stojkovi? Aleksa Stojkovi? Apr 26, 2024
Read Article Manor Lords Settlement Level Upgrade Requirements Category: Guides Guides Manor Lords Settlement Level Upgrade Requirements Aleksa Stojkovi? Aleksa Stojkovi? Apr 26, 2024
Read Article How to Store Exposed Goods in Manor Lords Category: Guides Guides How to Store Exposed Goods in Manor Lords Lewis Rees Lewis Rees Apr 26, 2024
Read Article All Resources & How to Farm Them in Manor Lords Category: Guides Guides All Resources & How to Farm Them in Manor Lords Aleksa Stojkovi? Aleksa Stojkovi? Apr 26, 2024
Read Article Are There Manor Lords Cheats? Category: Guides Guides Are There Manor Lords Cheats? Aleksa Stojkovi? Aleksa Stojkovi? Apr 26, 2024
Read Article How to Get Planks in Manor Lords Category: Guides Guides How to Get Planks in Manor Lords Rowan Jones Rowan Jones Apr 26, 2024
Read Article Shakes and Fidget Codes (April 2024) Category: Codes Codes Guides Guides Shakes and Fidget Codes (April 2024) Gabriela Jessica Gabriela Jessica Apr 25, 2024
Read Article Hero Clash Codes | Free Diamonds (April 2024) Category: Guides Guides Codes Codes Hero Clash Codes | Free Diamonds (April 2024) Aleksa Stojkovi? Aleksa Stojkovi? Apr 25, 2024
Read Article Free Monopoly GO Dice Links (April 25, 2024) Category: Codes Codes Guides Guides Free Monopoly GO Dice Links (April 25, 2024) Zhiqing Wan Zhiqing Wan Apr 25, 2024
Read Article Roblox Mechanic Legends Codes | New Code (April 2024) Category: Codes Codes Roblox Mechanic Legends Codes | New Code (April 2024) Aleksa Stojkovi? Aleksa Stojkovi? Apr 23, 2024
Read Article Fairy Tail Fierce Fight Codes (April 2024) Category: Codes Codes Fairy Tail Fierce Fight Codes (April 2024) Aleksa Stojkovi? Aleksa Stojkovi? Apr 15, 2024
Read Article Manor Lords Early Access Review?– Strategy Game of The Year Candidate… In a Few Years Category: Reviews Reviews Manor Lords Early Access Review?– Strategy Game of The Year Candidate… In a Few Years Aleksa Stojkovi? Aleksa Stojkovi? Apr 25, 2024 3 stars
Read Article Sand Land Review – Akira Toriyama’s Timeless Legacy Category: Reviews Reviews Sand Land Review – Akira Toriyama’s Timeless Legacy Syed Hamza Bakht Syed Hamza Bakht Apr 24, 2024 4 stars
Read Article Stellar Blade Review – Stylish Action Above All Category: Reviews Reviews Stellar Blade Review – Stylish Action Above All Jake Su Jake Su Apr 24, 2024 3.5 stars
Read Article Best Export Resources in Manor Lords Category: Guides Guides Best Export Resources in Manor Lords Was there a Davos-like forum in medieval times? Aleksa Stojkovi? Aleksa Stojkovi? Apr 26, 2024
Read Article Manor Lords Complete Trading Guide Category: Guides Guides Manor Lords Complete Trading Guide I wish my peasants knew to always tip their manor lord... Aleksa Stojkovi? Aleksa Stojkovi? Apr 26, 2024
Read Article How to Store Exposed Goods in Manor Lords Category: Guides Guides How to Store Exposed Goods in Manor Lords Build to Live Lewis Rees Lewis Rees Apr 26, 2024
Read Article Are There Manor Lords Cheats? Category: Guides Guides Are There Manor Lords Cheats? You know what happens to those that try to cheat lords? Aleksa Stojkovi? Aleksa Stojkovi? Apr 26, 2024
Read Article Manor Lords Settlement Level Upgrade Requirements Category: Guides Guides Manor Lords Settlement Level Upgrade Requirements How big can your settlement even get? Aleksa Stojkovi? Aleksa Stojkovi? Apr 26, 2024
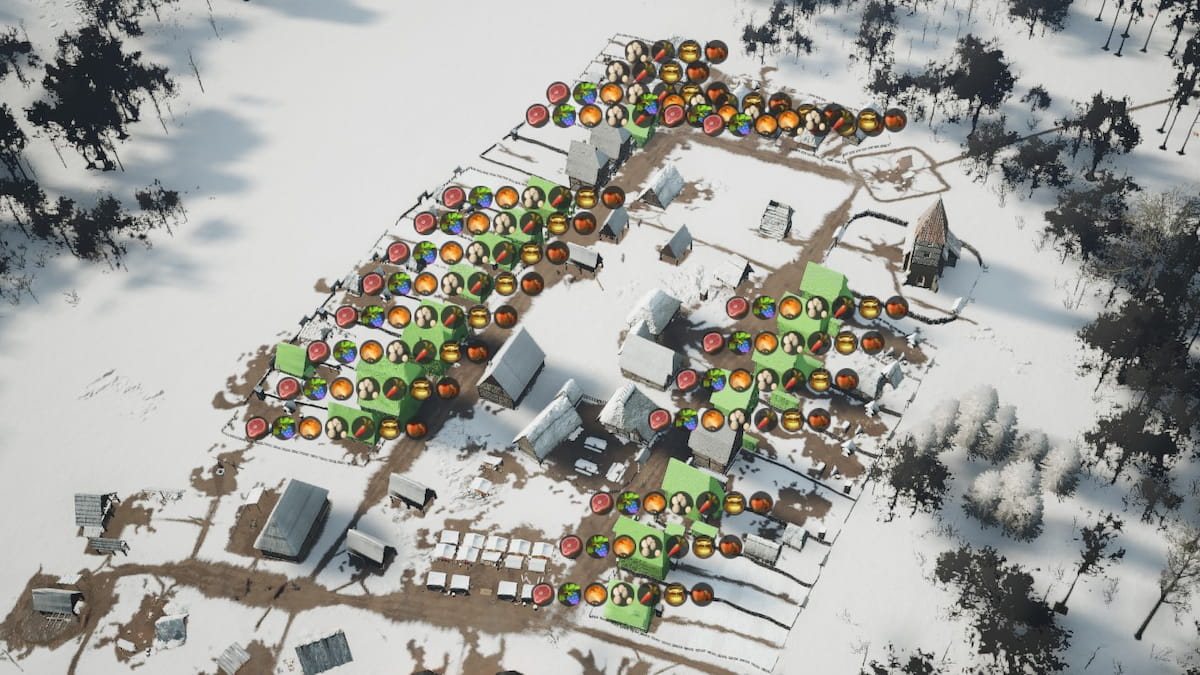
Read Article All Resources & How to Farm Them in Manor Lords Category: Guides Guides All Resources & How to Farm Them in Manor Lords What if I just want to trade for them instead of making them? Aleksa Stojkovi? Aleksa Stojkovi? Apr 26, 2024
Read Article How to Get Planks in Manor Lords Category: Guides Guides How to Get Planks in Manor Lords From mighty trees come ... mighty planks Rowan Jones Rowan Jones Apr 26, 2024
Read Article Easiest Way to Get Influence in Manor Lords Category: Guides Guides Easiest Way to Get Influence in Manor Lords Almost feels like cheating. Aleksa Stojkovi? Aleksa Stojkovi? Apr 26, 2024
Read Article How to Get Rooftiles in Manor Lords Category: Guides Guides How to Get Rooftiles in Manor Lords Rooftiles are a hugely important resource. Luke Hinton Luke Hinton Apr 26, 2024
Read Article How to Build Walls & Gates in Manor Lords Category: Guides Guides How to Build Walls & Gates in Manor Lords If you build it, they will come. Aleksa Stojkovi? Aleksa Stojkovi? Apr 26, 2024
Read Article Hero Clash Codes | Free Diamonds (April 2024) Category: Guides Guides Codes Codes Hero Clash Codes | Free Diamonds (April 2024) Aleksa Stojkovi? Aleksa Stojkovi? Apr 25, 2024
Read Article What is the Globle Today? (April 2024) Category: Guides Guides What is the Globle Today? (April 2024) Dylan Chaundy and others Dylan Chaundy and others Apr 25, 2024
Read Article Demon Piece Trello Link Category: Guides Guides Roblox Roblox Demon Piece Trello Link Gabriela Jessica Gabriela Jessica Apr 24, 2024
Read Article Jujutsu Legends Phantom Siege Codes (April 2024) Category: Guides Guides Codes Codes Jujutsu Legends Phantom Siege Codes (April 2024) Luke Hinton Luke Hinton Apr 23, 2024
Read Article Remnant 2 Forgotten Kingdom DLC Release Time Countdown & All New Features Category: Guides Guides Remnant 2 Forgotten Kingdom DLC Release Time Countdown & All New Features Cameron Waldrop Cameron Waldrop Apr 23, 2024